Canonicalization is the process of presenting the document unambiguosuly in a
non-homogenous environment, and plays an important role in signing and
verifying digital signatures. When a document is passed through the
internet, some forwarding agents modify the document to the way their local
systems interpret character sets and line delimiters. When the
document is modified, this same document may be forwarded to the next transfer
agent who may likewise make other modifications before forwarding to the next
transfer agent. The final recipient is no longer guaranteed that the
document received is the original document from the sender even though a
"harmless" transfer occurred along the way. Under this same condition, if
the document is digitally signed by the sender, the recipient would not be able
to verify the same document. Therefore, the document has to be
canonicalized so that there is only one way in which the document can be
interpreted across transfer agents and local systems. When the
canonicalized document is signed on the sender side, it can be verified on the
receiving side.
Some of the different ways in which transfer agents and local systems interpret
the document may be:
Text-based presentations on local systems handle line delimeters using the
single carriage-return character (CR), or single line feed character (LF), or
carriage-return line-feed sequence (CRLF).
For text-based presentations, trailing spaces at the end of the line may or may
not be stripped.
Character sets in a message body containing binary data may or may not be
recognized by local systems.
Required Steps for Canonicalization
When a document is canonicalized, it is modified as follows:
Encode the document using 7-bit character set. So that binary data is
represented unambiguously, it must be represented in a 7 bit character set, and
that the characters in the character sets are recognized in all systems.
This is noramlly done by encoding the header and body of the document with a
Base64 or Quoted-Printable 7-bit encoding mechanism. The
Content-Transfer-Encoding header is then added with the applied encoding
mechanism name assigned as its value
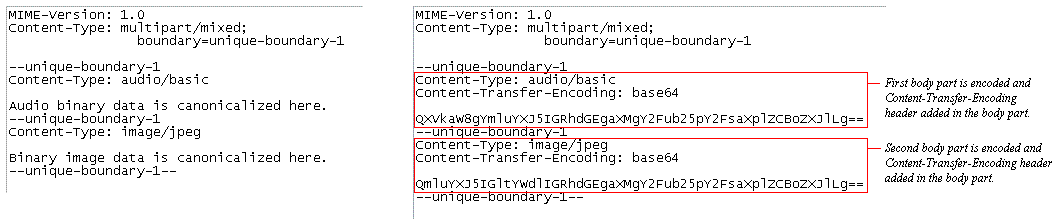
For a message containing multiple body parts, each of the individual body parts
are encoded as though they were separate messages. That is, since each
body part both contain a header and body, the body is encoded to the 7 bit
encoding mechanism and, in the same context, the Content-Transfer-Encoding
header is added with the information of the encoding mechanism. NOTE: The
encoding mechanisms in each of the body part may differ from the other.
For example, one body part may be encoded in Base64 and another body part in
the same message could be encoded in Quoted Printable.
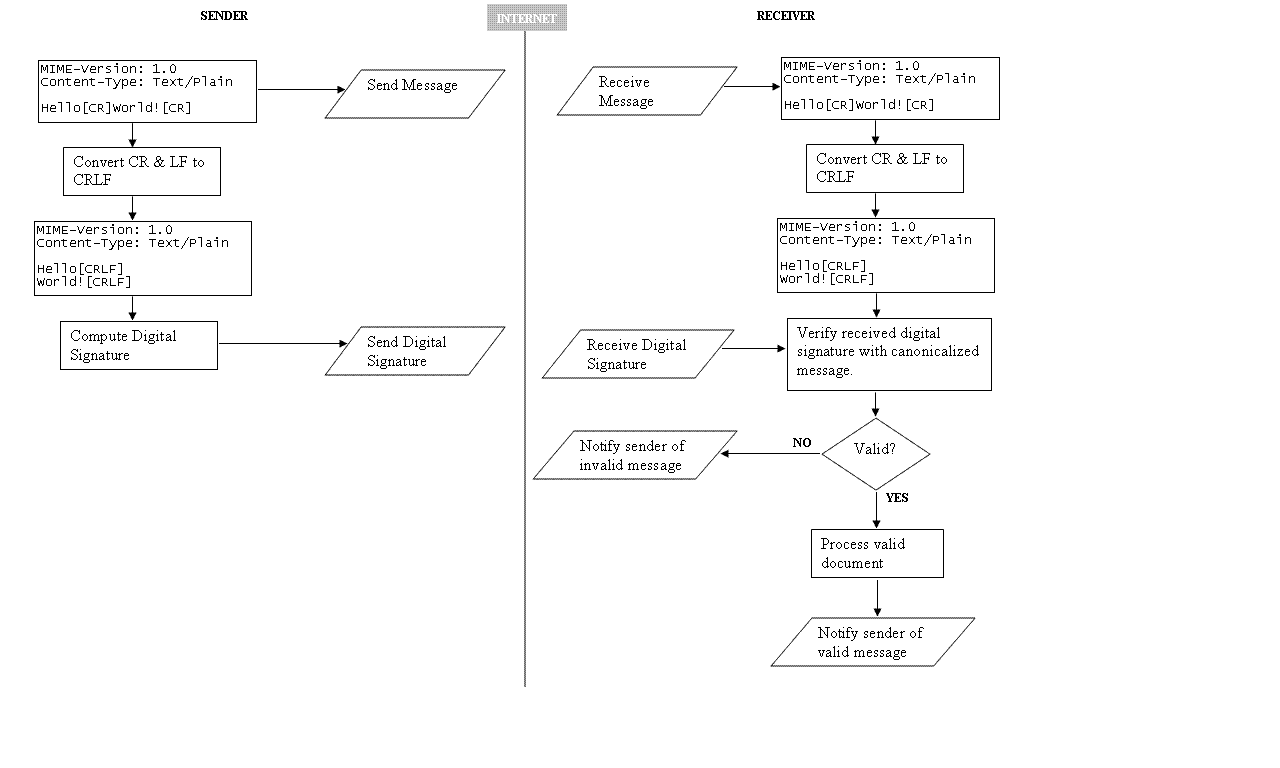
If the document is already defined to be text (7-bit) then any occurrences of
single carriage returns (CR) and single line feeds (LF) are converted into the
canonical line delimiter CRLF sequence. The CR and LF characters have
octet value 13 (0xD) and 10 (0xA) respectively. This conversion is
required only for computing the digital signature on the document, and the the
original document without the conversion must be sent to the trading
partner. When the trading partner receives the document, the CRLF
conversion must be done before computing the digital signature.
Because of the many different possible representations of data that are
processed and transfered, the question of whether data is canonicalized or not
has to be determined. A MIME document is composed of two sections: a
header and a body. Framework EDI only reads MIME documents whose header
is already canonicalized, i.e. all characters in the header are 7-bit and are
all terminated using the line delimiter CRLF canonical form. In the same
token, Framework EDI prepares MIME documents with properly canonicalized
headers. Therefore, when preparing and processing, only the body is
canonicalized. As always, Framework EDI plays on the side of caution
from automatically modifying data, and it takes the followings steps to
determine if the body should be canonicalized before undertaking the process.
The body is scanned to check if it is already in 7-bit. In a multipart
message, all body parts are scanned including all nested body parts to check if
it is already in 7-bit. If the body is already in 7-bit then no
canonicalization is performed. This check is done whether the body
contain text or binary data. If binary data contain only 7-bit bytes then
no canonicalization is done.
If the body is not in 7-bit, the body is encoded using the encoding mechanism
that is applicable to the content described by the Content-Type header.
Currently, Framework EDI encodes the content types as follows:
Application/EDI-X12 is encoded to Quoted-Printable.
Application/Edifact is encoded to Quoted-Printable.
Application/EDI-Content is encoded to Quoted-Printable.
All other content types are encoded to Base64.
If the Content-Type header and the Content-Transfer-Encoiding are missing the
data is encoded to Base64.
If the body is described as having Content-Type Text/* or some 7-bit type, or
the Content-Transfer-Encoding describes a 7-bit encoding mechanism then no
transfer encoding is done, and a warning is generated stating that the body
contain binary data.
If the Content-Transfer-Encoding header exists and currently has the name of the
specified encoding mechanism then no encoding is done, and a warning is
generated stating that the body contain binary data.
If the Content-Transfer-Encoding header exists and the body is encoded in the
specified encoding mechanism then the header is assigned the name of the
encoding mechanism applied. For example, if the Content-Transfer-Encoding
originally has the name "binary", and the body is encoded in Base64 then the
new value of the header is assigned the name "base64".
If the Content-Transfer-Encoding header does not exist and the body is encoded
in the specified encoding mechanism then the headers is added and assigned the
name of the encoding mechanism applied.
When the message is in 7-bit, the entire message is scanned and all single CR
and single LF characters are replaced by the CRLF sequence. The message
may have been transfer encoded to arrive to its 7-bit character presentation,
or the message may already be defined as text. In either case, the CRLF
conversion is still required. This conversion is required only for
calculating the digital signature. The resulting text after the CRLF
conversion must not be sent, and only the text prior to the cnversion is
sent. When the message is received on the other end, the recipient must
do the same conversion of replacing all single CR and LF with the CRLF sequence
before computing the digital signature.