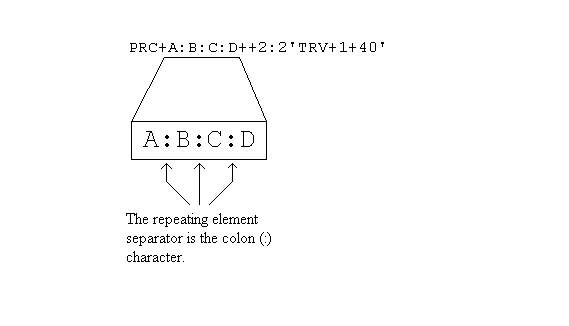| Delimiters |
Other notations which can be specified in UN/EDIFACT:
Delimiters in a document cannot be the same. That is, the data segment terminator character must be different to the data element separator character, which must be different to the component element separator, and so on. The character is "instructive" and lets the processor know what type of data is being separated.
NOTE: The words "terminators", "delimiters", and "separators" are used interchangeably in the online documentation.
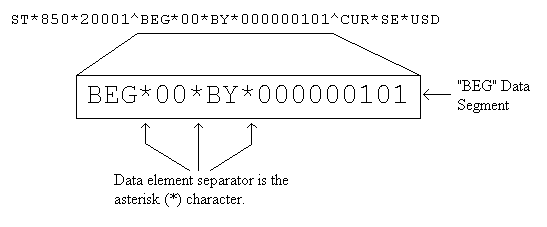
The data segment terminator separates the data segments in an EDI document. For example, the string below contains three data segments: "ST", "BEG" and "CUR". Each data segment begin with their identifier followed by a string of data elements, and then terminates with the data segment terminator. The next data segment begins thereafter.
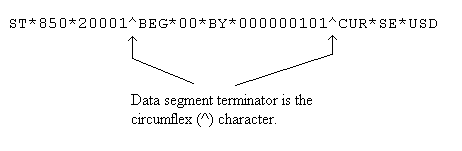
The data element separator is the character that separates data elements and/or composite elements in a data segment. For example, the data segment with identifier "BEG" contain the data elements "00", "BY" and "000000101". Each data element is separated from the other by the data element terminator character: "*".
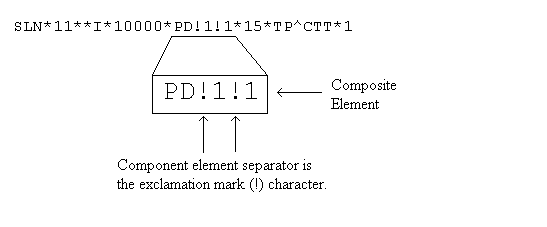
The component element separator is the character that separates the sub elements, or component elements, in a composite element. The composite element in the data segment does not begin with a composite identifier, and only the sub elements fill the segment at the position. In the example below, the composite element fills the 5th position of the "SLN" data segment. The composite element contain the sub elements "PD", "1" and, again, "1". The elements are separated by the component element separator "!". Note that the composite element separator "!" differs from the data element separator character: "*".
The repetition separator is a character that separates repeating occurrence of data elements or composite elements in the same position within the same data segment context. It is similar to a component element terminator, where a character separates discrete data elements in a data segment, but with the repeating element separator the item separated is of the same data element or composite element that repeats at the same location. In the example below, the data segment "PRC" contain data elements separated by the data element separator character: "+". The second position of the data segment is populated by repeating elements "A", "B", "C" and "D", separated by the repeating element separator: ":".
The decimal notation is the character used to represent the decimal point. By default, this is the period or the full stop (.), but in some cases can be a comma (,).
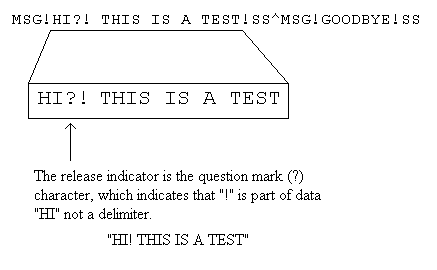
The release indicator is a character that precedes a delimiter character to indicate that it is not a delimiter but rather part of data. In the example, the data segment "MSG" contain data elements that are separated by the exclamation mark ("!") character. However, the value "HI! THIS IS A TEST" contain the character "!", and cannot therefore act as a delimiter. The release indicator character is a question mark ("?") and is placed in front of the exclamation mark, like: "?!". When such a sequence is encountered, the character "!" is ignored as a delimiter and included as data.